
The Four Data Engineering Archetypes that Dominate in 2026
The four most impactful types of data engineer in 2026 are the Generalist data engineer, Data Platform Engineer, AI/ML Data Engineer, and Data Quality Engineer. Learn how and when each are needed.

Introduction
Data engineering in 2026 is no longer a single job title. Over the last two decades it has evolved into specialized roles that emerge as an organization’s data maturity grows. Now we have distinct archetypes, each optimized for different stages of scale, complexity, and risk that data teams go through.
I’m going to outline what I consider to be the four data engineering archetypes that matter most in 2026: the Generalist data engineer, the Data Platform Engineer, the AI/ML Data Engineer, and the Data Quality Engineer. These roles don’t replace one another; they layer on top of each other as needs evolve.
I’m sure people will notice (and maybe get grumpy about) the absence of the Analytics Engineer but this is an intentional choice. I understand the ideology behind the analytics engineer role but in practice, analytics engineering has become implicitly embedded across all four archetypes. Data modeling, semantic layers, metric definitions, and analytics-ready transformations are now core expectations of modern data engineers, especially generalists and platform engineers. Rather than treating analytics engineering as a separate specialization, this article assumes it as a foundational capability that shows up across all four discussed archetypes.
The goal here isn’t to create rigid job titles, but to provide a decision framework to help you decide which type of data engineer you actually need, when you need them, and why most teams should resist premature specialization. Most companies start with one role, scale into another, and only a few ever need all four. This is outlined in Figure 1 visually show the chasm that separates roles; the vast majority of companies only ever need two roles; the generalist and data platform engineers.
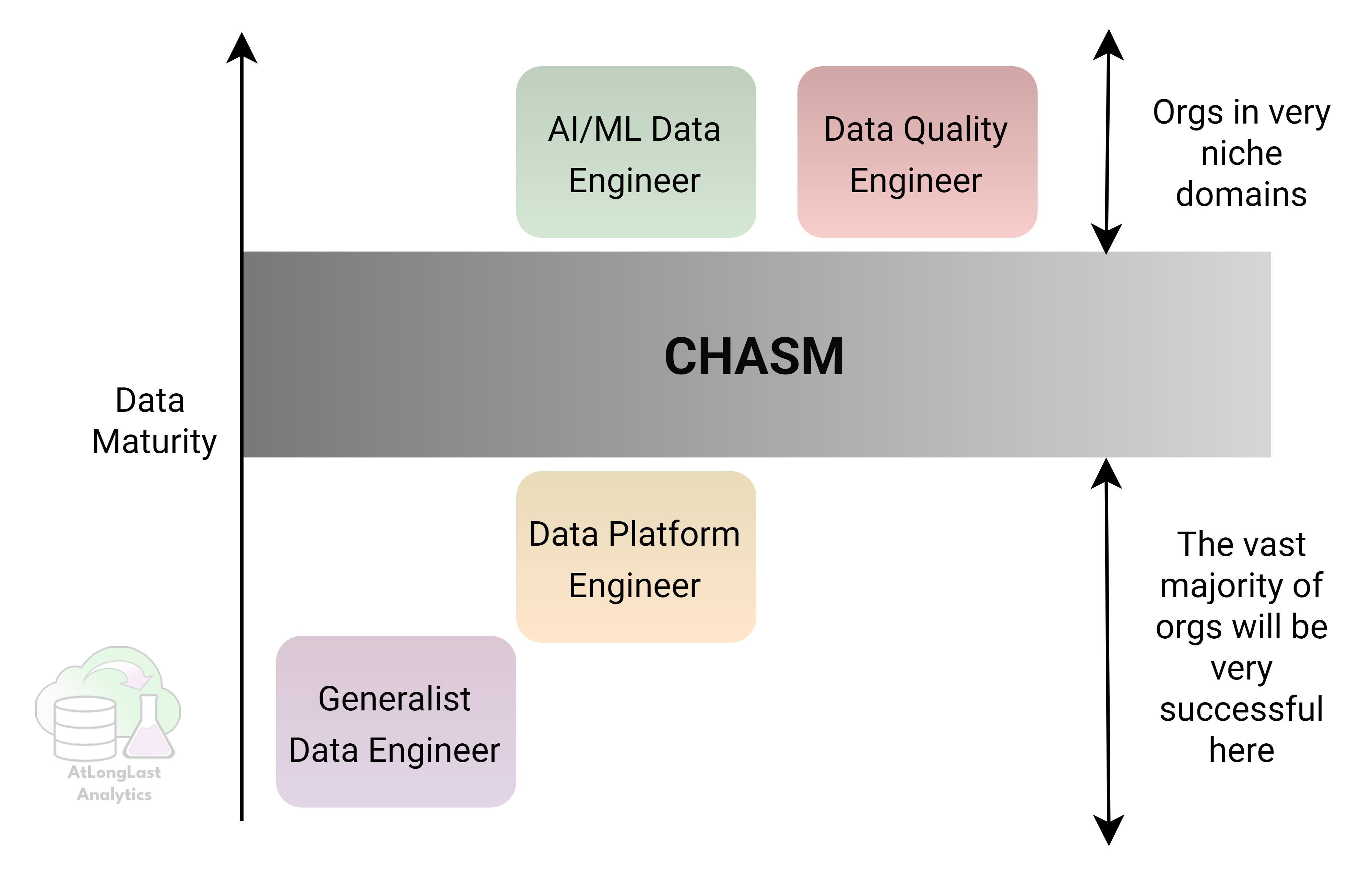
p.s. I also hope this can help early career data engineers choose which path of specialism they want to go down so they can be intentional in their development.
Four Data Engineering Archetypes in 2026
Let’s dive into how I think how about data engineer archetypes, their role and responsibilities and where they fit into the data maturity journey.
1. The Generalist Data Engineer
All data engineers start out as the generalist and this role forms the backbone of most data teams. They typically own the end-to-end of process of data ingestion, cleaning, modelling, and serving data in a useful form for analytics and BI.
The best generalists understand the business just as well as they do pipelines. Every data team starts here but even in 2026 many never need to go further.
As a generalist you’re primary responsibilities are:
to keep everything running (which means debugging everything when it breaks)
maintaining high quality data for end-users
owning new data integrations
Your skillset is heavily Python and SQL focused but also requires broad awareness of data storage solutions (data warehouses and data lakes) and basic analytics. You’ll likely need to be fluent in a cloud-native stack from one of the big three; for Azure this means Azure Data Factory, Fabric, Synapse and PowerBI.
The most underrated skill for all data engineers is being able to speak the language of your data consumers. Being able to translate between business needs and data solutions is how you stand out and be someone that others want to work with.
2. The Data Platform Engineer
The data platform engineer separates themself from the generalist because they don’t spend all of their time building datasets, instead they focus on building the infrastructure and systems that let other people safely build datasets. Platform engineers give the generalists the tools to handle data repeatedly, and at scale.
A good data platform engineer can unblock and accelerate tens of generalist engineers by building systems. As cloud adoption rises so does this role’s value.
As a platform engineer, you’re responsible for data infrastructure:
designing lakehouse/warehouse architecture
implementing security, governance, and access controls
optimizing cost, performance, and uptime
managing CI/CD for data pipelines
A platform engineer’s skillset is much more specialized than the generalists’. You need to understand CI/CD practices and resource management; this includes everything from deployment using Infrastructure-as-code to FinOps. To excel in this role you need to master orchestration frameworks and cloud management.
I see a lot of platform engineers understand the technology but not how it links to helping solve specific business problems; if you can’t tell me how that new Azure component delivers quantified value then you need to round out your skills.
3. The AI/ML Data Engineer
ML and AI data engineers are unique in that they’re not focused on feeding dashboards but instead on powering models. Their value proposition comes from making data usable for training, inference, and AI-driven data products.
A lot of companies think they need dedicated AI and ML engineers but few actually do. Unless AI is directly tied to revenue or core workflows, this role is usually filled prematurely.
Core responsibilities include:
feature engineering and building feature stores
managing training and inference pipelines
supporting RAG, embeddings and vector search
data versioning, freshness, and consistency
AI/ML engineers need a solid understanding of AI-powered products and how to ensure that they run continuously in production. You need to combine data engineering best practices with vector databases, ML orchestration and monitoring, and feature stores.
Many data scientists in the 2000s would build a cute machine learning in a notebook but in 2026 we need AI/ML engineers to understand deployment. You can stand out by taking the business’ availability and accuracy needs and architecting solutions that meet these by using techniques like blue-green deployment (when reviewing candidates, I see a lot of gaps in aspiring AI/ML Data Engineers today).
4. The Data Quality Engineer
Data quality engineers exist to protect the business from bad data. Unlike other data engineers, their primary customer is not analytics or AI teams - it’s risk, compliance, and operations. In highly-regulated domains incorrect data can trigger fines, patient harm, or even operational shutdowns, quality is no longer just a “nice to have”.
Data quality engineers rarely exist outside of regulated industries like healthcare and defense. However, in regulated domains data quality is mission-critical, with data quality engineers often outnumbering AI/ML engineers.
Core responsibilities include:
regulatory compliance support (HIPAA, SOC2, GDPR, etc.)
incident response for data quality failures and issues
data validation, auditability, and lineage
schema enforcement and data contracts between systems
Data quality engineers specialize in data quality frameworks, metadata management and data lineage tools to ensure that all compliance rules are met. They combine advanced SQL skills with deep domain knowledge whilst working closely with legal, compliance, and business stakeholders to translate abstract rules into concrete technical implementation.
This role tends to emerge late in a company’s data maturity but once it does, it becomes almost impossible to operate without it. In regulated environments, data quality engineers are the difference between scaling safely and fire fighting.
Bringing It All Together
Every data capability starts with generalists. This role is foundational: it’s how you initially extract value from data, learn the key business questions that need to be answered, and build pipelines that actually get used. Strong generalists build momentum and get buy-in for the new data capability. If you are a founding data engineer, communication is THE most important skill for a successful data team.
As data usage grows, teams will hit a wall. This is where bringing in a data platform engineer can unblock your data team by standardizing infrastructure, tooling, and ways of working, empowering generalists to work faster without compromising quality. For most organizations, building a team of generalists plus a small number of platform engineers is enough to build a very successful (profitable) data team.
Beyond that lies a clear chasm (see Figure 2(. AI/ML data engineers and data quality engineers only make sense when driven by specific business needs: AI as a core product or revenue driver, or regulatory environments where data quality is mission critical or data errors carry sever consequences. Hiring for these roles without these pressures usually results in expensive data teams that lose C-suite buy-in and end up losing funding or ceasing to exist all together.
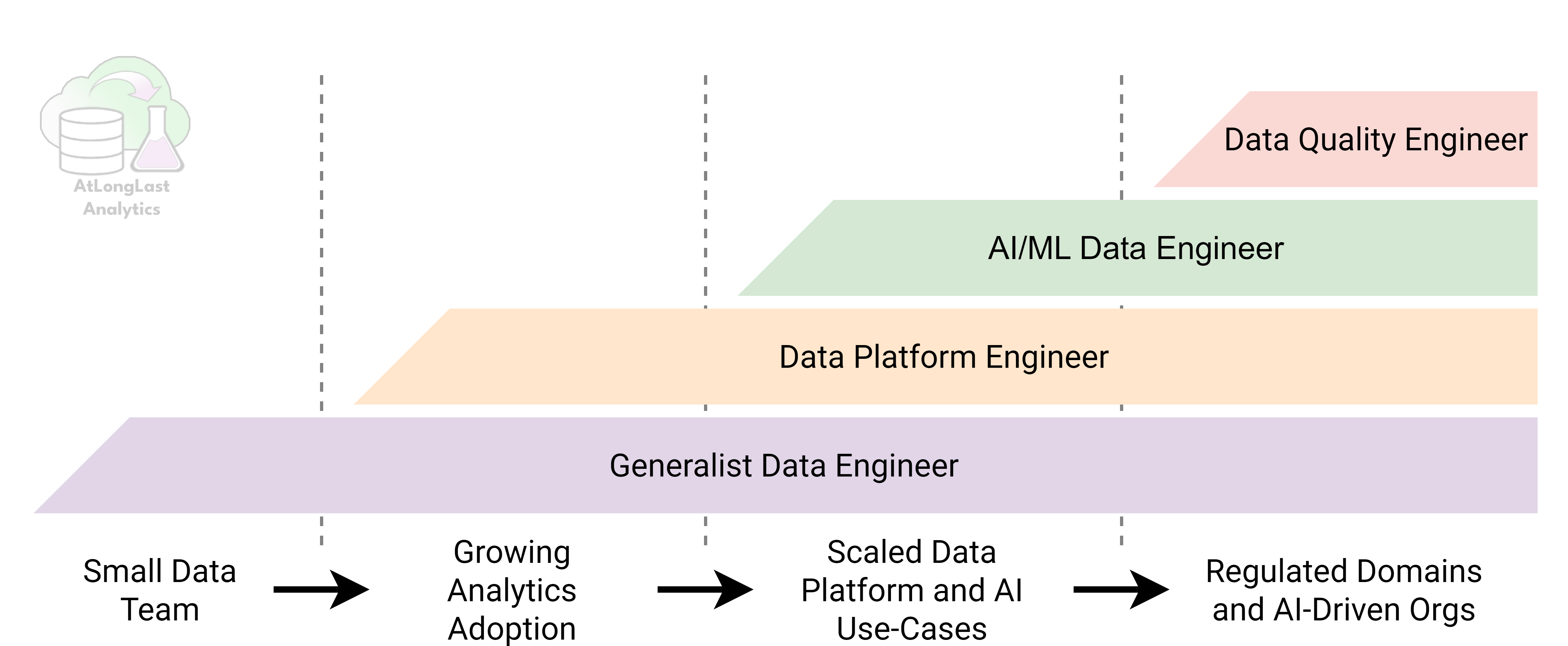
The key takeaway is that data teams should evolve intentionally and not based on yet to be realized aspirations. Most companies don’t need all four archetypes and that’s perfectly fine. The right team is not the one with all the fancy titles, it’s the one that aligns its skills to the problems the business actually has today, while leaving room to grow to address tomorrow’s problems.
Thanks for reading! Feel free to follow us on LinkedIn here and here. See you next time! To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.