
Quality Assurance and Quality Control in Data Engineering
A practical guide to preventing defects and validating outcomes in your data pipelines. Learn how to safeguard your analytics and ensure every metric for decision-making.
Read time: 3 minutes
Modern organizations depend on data to make decisions, automate processes, and measure performance. As the volume and complexity of data ecosystems grow, so does the impact of errors. A single incorrect revenue metric can alter a forecast; a broken pipeline can disrupt downstream workflows; a small unnoticed bug can propagate and quietly corrupt metrics consumed by the entire C-suite.
To build trust, teams need more than clever data models and cloud platforms.
They need discipline and consistency.
This article provides a practical introduction to Quality Assurance (QA) and Quality Control (QC) in the context of data engineering and analytics. This provides the foundation for reliable data products.
Why QA and QC Matter
Data teams have evolved. They are no longer isolated report builders; they function like software engineering teams; they write code, manage environments, and operate production systems. Like all engineering disciplines, quality cannot be optional.
Without structured QA and QC, teams face predictable risks:
Pipeline failures when upstream systems change
Contradictory dashboards that confuse consumers
Models drift silently degrades decision quality over time
Loss of trust, leading stakeholders to bypass data teams entirely
QA and QC are the mechanisms that prevent these issues and detect them quickly when they occur.
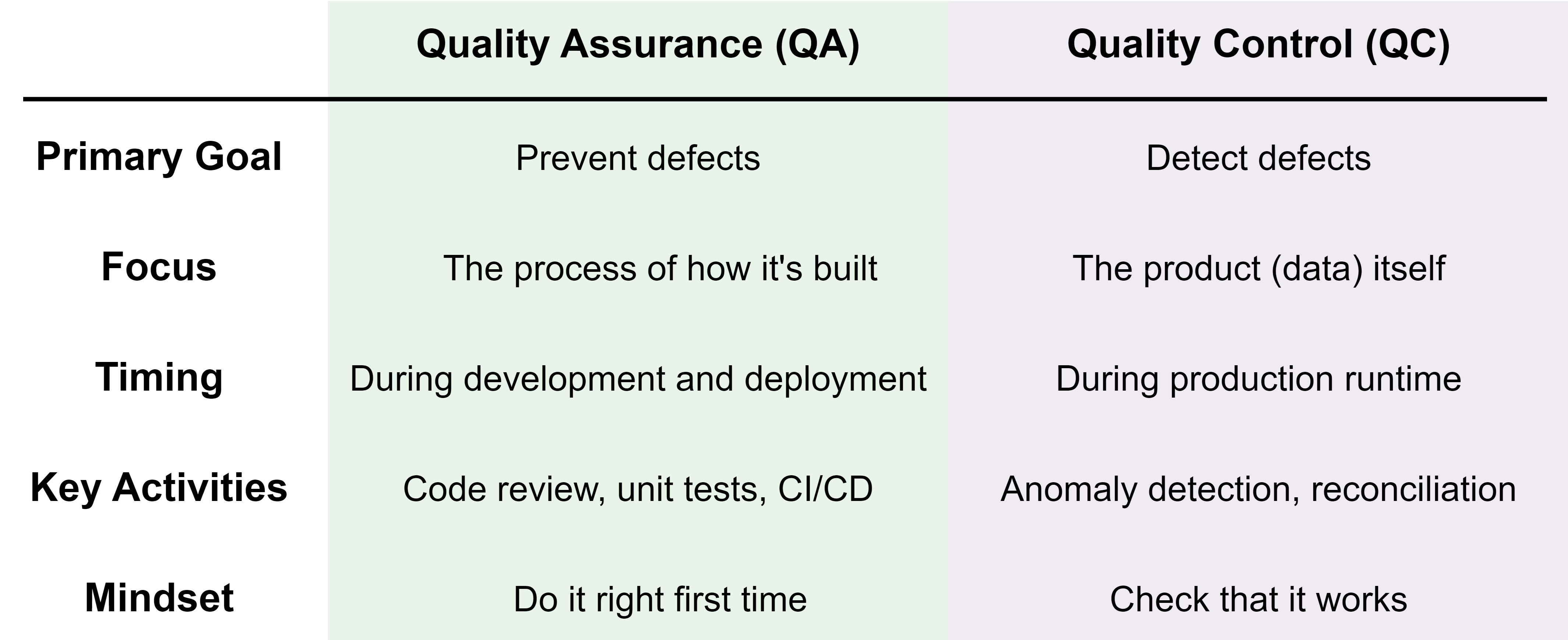
What is Quality Assurance (QA)?
Quality Assurance is about building reliable systems and processes. It focuses on how the work is done, rather than testing the final output.
Think of QA as creating the conditions under which high-quality data products are likely to be produced.
In data engineering and analytics, QA includes:
Coding and Modeling standards: enforcing naming conventions and directory structures
CI/CD pipelines: automated test suites that run on every code commit
Code reviews: peer review to catch logic errors before merging
Environment Management: strict separation between Dev, Test and Prod
QA prevents defects by ensuring consistency, clarity, and rigor across the development lifecycle.
Consider the scenario: A team is building a new pipeline to extract sales data from an API and loads it into a data lake.
Pull Request: a developer submits code
Static Analysis: The CI pipeline automatically checks for naming conventions and SQL syntax errors
Unit Tests: automated tests verify that the API client handles pagination and data parsing correctly
Outcome: The pipeline cannot be deployed until it passes these checks. No real data has moved yet. This prevents defects by ensuring the logic is sound.
What is Quality Control (QC)?
Quality Control is about validating and monitoring outcomes. It focuses on the correctness of the data itself.
If QA is ‘designing a good process’, QC is ‘inspecting the product’.
In data workflows, QC includes:
Data Validation: Null checks, referential integrity, and schema validation.
Freshness Checks: Ensuring data arrives on time, in agreement with SLAs.
Anomaly Detection: Spotting volume spikes or drops (e.g. row count deviations of 3% or more)
Reconciliation: Comparing warehouse totals against source system totals
Consider the scenario: The pipeline is now in production and yesterday’s data has landed.
Freshness check: a job verifies data has arrived before 05:00
Volume check: the system compares today’s row count to the 30-day average
Business logic: a rule verifies that Total Sales falls within an acceptable range
Outcome: if the row count is 50% lower than usual, an alert fires, and the data is quarantined so it doesn’t reach the executive dashboard
Summary
A Simple Framework for Getting Started
You don’t need some huge initiative to improve quality. Adopt a maturity model approach:
Define Standards (QA): Establish naming conventions, directory structures, and pull request templates.
Introduce automated testing (QA): Add basic unit tests to your CI/CD pipelines (e.g. testing transformation logic)
Add monitoring and observability (QC): Start monitoring freshness (is it new?), volume (is it all there?), and schema drift.
Gate deployments: Require automated sign-offs before promoting code from Dev to Prod.
Continuously improve: Track and review incidents and strengthen QA/QC processes based on lessons learned.
Conclusion
Reliable data isn’t a byproduct of good intentions or talented engineers, it’s the result of intentional habits. Quality Assurance ensures pipelines are built with rigor, while Quality Control ensures that the data they produce is accurate and trustworthy.
By implementing both together, you reduce the cost off errors, increase team velocity, and provide stakeholders with confidence that the data empowers good decisions.
Thanks for reading! Feel free to follow us on LinkedIn here and here. See you next time! To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.