
What roles exist in the modern data team?
The overlap between data job roles leads to conflicting definitions across organizations. We propose a simplified taxonomy for the data governance and implementation team.

Read time: 5 minutes
Summary
Business leaders all too often want to dive straight into the latest and greatest AI, but it is our responsibility as data professionals to communicate that this is a formula for failure. Data analytics, machine learning, and artificial intelligence are all reliant on having timely, accurate, high-quality data to drive meaningful impact. Similarly, to ensure that there is consistently good quality data, there must be over-arching data management protocols and standards established within the organization.
This brings us to the ultimate superhero team-up of The Key Three who implement governance and management with the analytics and engineering team known as The Core Four.
Let’s dive into what makes up the core responsibilities of a data team, map these to a concise and consistent group of roles and see which roles didn’t make the cut!
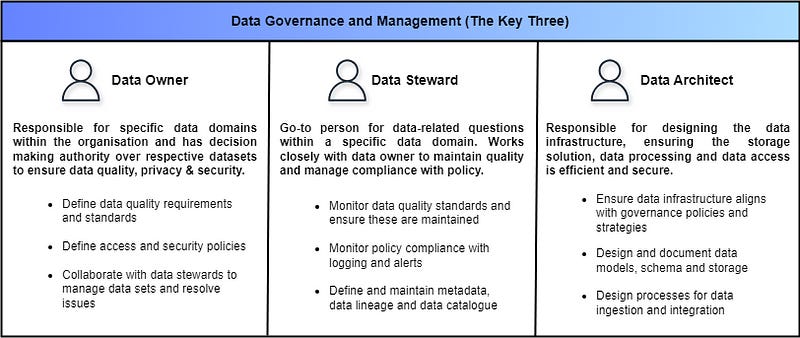
The Key Three — Governance and Management
Data management and governance strategy are vital components of the modern data team. These and all underlying responsibilities are shared between the Key Three, consisting of the data owner, the data steward and the data architect.
The data owner is typically a senior business leader who is responsible for specific data domains within the organization. The data owner has the decision-making authority over their respective datasets and must ensure data quality requirements and standards are robustly defined. Similarly, the data owner must ensure that a robust set of privacy and security policies are defined and followed.
The data steward works closely with the data owner but their involvement is more hands-on, they proactively monitor data quality and policy compliance. The data steward is often the “go-to” person for data-related questions within a specific data domain, acting as an interface between the technical team and the data owner.
The final member of the Key Three is the data architect. The architect is the most technical of the three and is responsible for designing and maintaining the data infrastructure in line with the policies and standards outlined by the data owner. In addition to infrastructure responsibilities, the architect creates high-level designs for data flows, schema, and storage in alignment with the data governance strategy.
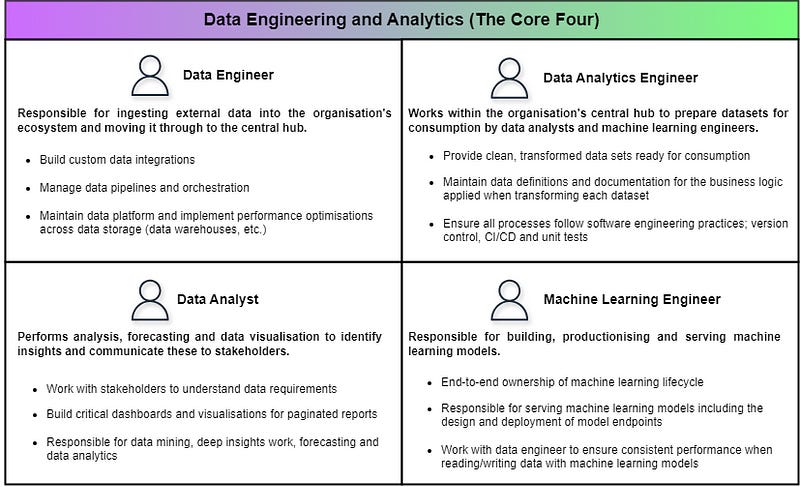
The Core Four — Engineering and Analytics
The technical team consists of four roles whose responsibilities cover all activities within the end-to-end data journey. The Core Four is made up of the data engineer, data analytics engineer, data analyst, and machine learning engineer.
Data engineers are a lynchpin of the modern data team with strong technical ability across both data and software engineering. The data engineer’s primary responsibility is to ingest external data into their ecosystem and ensure it flows from the landing zone through to the central hub. Other duties include the deployment and optimization of data storage (data lakes, data warehouses, etc.) and working with the analytics engineer to design data models.
The analytics engineer mostly works within the central hub picking up where the data engineer has left off. They ensure clean, transformed datasets are ready for consumption by data analysts and machine learning engineers. The analytic engineer is focused on underpinning all workloads with best practices including version control, unit tests, and CI/CD. A key deliverable of the analytics engineer is up-to-date documentation combining data dictionaries with applied business logic.
Now that clean datasets have been delivered by the analytics engineer, the data analyst is able to consume these datasets and carry out deep insight work and forecasting. The analysts are responsible for delivering critical dashboards and working closely with business users to understand changing data requirements.
The technical team is rounded out by the machine learning engineer (MLE). The MLE is responsible for all things machine learning, including building ML models and deploying them to production. The MLE is similarly technical to the data engineer but is much more specialized in machine learning, including how to deploy endpoints and APIs. They understand how to properly train, advance, and serve models ensuring scalability and proper monitoring.
What roles weren’t included?
I am sure some people will question, what about the data scientist role? I have held the title of data scientist myself but in my view, this has always been a rather confusing title. Data scientist is a non-specific job title that in most instances acts as a catch-all for various tasks which fall within the data analyst or machine learning engineer roles within the core four framework. While I think that the data scientist role can be relevant within academia and some R&D departments (where they do a substantial amount of experimentation), it seems redundant in the modern data team. For more discussion on the topic I highly recommend checking out the “Down with data science” podcast by Emilie Schario.
What about BI (business intelligence) roles? The first issue is that there is some confusion over the title, is there sufficient breadth within business intelligence to have so many different titles; BI developer, BI engineer, BI analyst, etc.? The majority of responsibilities that fall under the various BI roles are shared with the data analyst role.
Unfortunately, there is a somewhat elitist attitude within parts of the data community, I have seen many instances where BI professionals are seen as glorified dashboard builders whereas data scientists are held in high esteem mainly owing to the air of mystique around the role. That data analyst role is the unsung hero of many teams now it seems about time to embrace MAGA — make analysts great again!
By not including these two roles, the framework that I propose helps to have a more consistent and transparent distribution of responsibilities by role.
Closing thoughts
The current data landscape is thriving — engineering and analytical workflows have matured to the point that we are now able to discuss the pros and cons of different roles and structures of data teams. Well-defined roles and responsibilities as highlighted in this article allow teams to efficiently recruit new staff and for teams to quickly identify specialists within their organization. Transparency and clarity about responsibilities, skillsets and technologies also has the benefit of defining learning journeys and paths for technical progression and promotion.
What this doesn’t mean is that any and all data teams need at least 7 people. In smaller companies it is very likely the case that one person will take on multiple of the roles outlined here. What this article aims to do is distinguish core responsibilities and tasks that need to be accounted for.
I believe the combination of the core four roles for the technical component and the key three for the management component provides a useful outline for data strategists to use when planning their data teams.
To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.