
Why I use Test-Driven Development as a Data Engineer
We discuss what test-driven development is, a practical 7 step process for implementing it, and highlight the benefits I get by using this in my day-to-day work as a data engineering consultant.

Read time: 8 minutes
Throughout my career, some of the most frustrating moments have been when I ran a data pipeline for the first time only for it to return an error, or even worse, a completely unexpected result. This could often lead to hours of effort finding and fixing issues which were easily avoidable had I approached the problem differently. This all changed once I started using test-driven development in my day-to-day work as a data engineer. Now, I spend much less time debugging and more time building solutions to answer the hardest problems.
For most of us, it makes sense to start a project with a design phase and then jump into implementation and writing code. This code-first approach frontloads effort on making something work and only when this passes the eye-test do we think to implement code tests. That’s assuming tests get written at all; I’ve seen a lots of cases where teams never write any tests at all… but that’s a story for a different day.
In this article, I’m going to discuss a test-first approach (formally known as Test-Driven Development) where we write code tests for a feature before writing any functional code. This is my preferred way of working and I think it’s a majorly under-utilized approach that is well-known in the software engineering community but rarely discussed in data engineering.
For an introduction to, or refresher on code testing then check out our article here.
What’s the difference between code-first and test-first development?
The code-first approach feels familiar because it mirrors the way we are taught to solve problems in school (read the question, attempt to solve the problem, and then review the steps/method). This isn’t inherently bad and definitely has its place in modern data engineering. If there are unclear requirements or you’re working on something more experimental, then the code-first approach can be very successful. I used it to complete my PhD research and to publish multiple academic papers.
In contrast, most data engineering tasks involve applying patterns to problems that have been solved before (or at least similar problems with small variations have). In these cases, a test-first approach is very useful because it give us a way to check our initial implementation and any future development.
Let’s do a one-to-one comparison to highlight the differences between the two methods. Both code-first and test-first approaches start with the design phase where we take a business problem, translate this to a data problem and then plan how we are going to solve it. The implementation phase differs between the two approaches with the code and test parts of the workflow swap places, hence the names code-first and test-first (see Figure 1). Both approaches end with refactoring, where we make sure our code is production ready (modular, follows a style guide, has comments and docstrings, etc.). If you’ve got this far and are wondering how you can write tests before the actual code that needs testing, then keep reading!

Now we’ve set the stage and challenged the status quo of how most data professionals build software, let’s dive into what Test-Driven Development looks like in practice.
What is Test-Driven Development?
Test-driven development, or TDD, is a way of building software by first writing small tests that describe how your code should behave. For data engineers, before starting to create a data pipeline or an application, map out your code components, and write tests to check that each part (like data cleaning, processing, or transformation) works as expected. These tests will fail at this stage as there isn’t any functional code yet. As you build out your solution, you run these tests to catch problems early, making debugging simpler and ensuring that future changes don't break working code.
In simple terms, TDD acts like a safety net, giving you confidence that your data pipelines remain reliable and accurate even as you make updates and add new features.
This approach obviously requires a mindset shift from focusing on implementation details to thinking about desired behavior and outcomes.
So how does it actually work?
If you look up test-driven development, you’ll find explanations which use the phrase “Red-Green-Refactor”. This describes TDD at a high level as a three step process:
Red: Write tests that fail (they have to fail as there is no functional code yet)
Green: Write just enough functional code so that the test(s) pass
Refactor: Clean up, comment, productionize the code
I think this is a good high-level overview but its hard to go from Red-Green-Factor to a practical implementation.
My 7 step process for using test-driven development
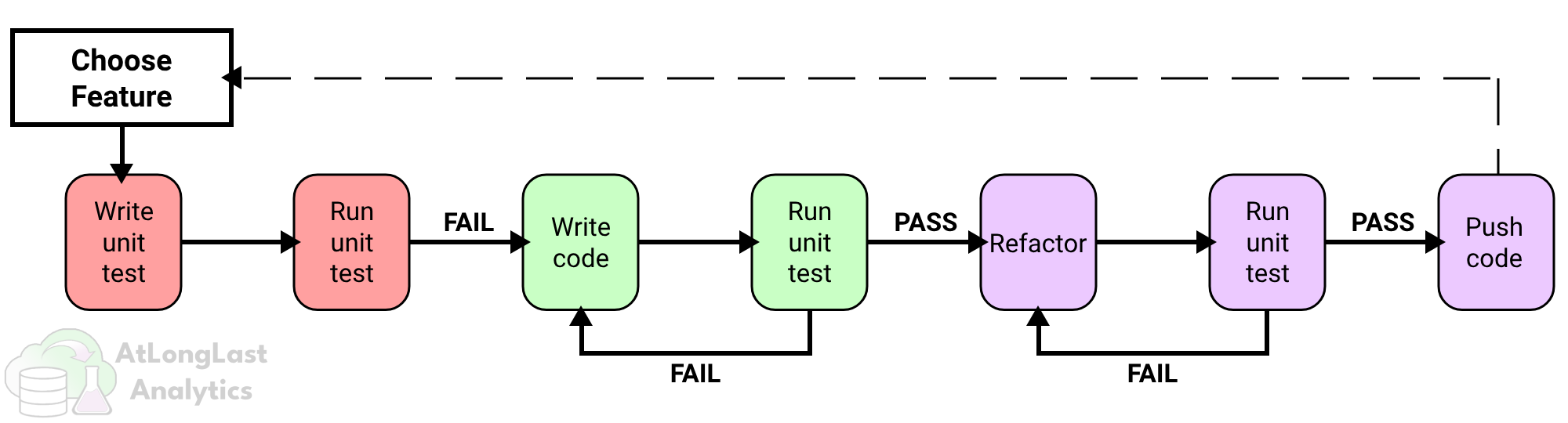
Here is the seven step process (shown visually in Figure 2) that I use to implement TDD in my data engineering work:
Choose a Feature: Choose a feature to work on.
Write a Test: Start by writing a test that defines the expected behavior or outcome of a specific task or component.
Run the Test: Run the test and watch it fail. For this step, failing is good!
Implement the Solution: Write the minimum amount of code for the test to pass.
Run the Test: Run the test again and confirm that the code passes the test. If it fails, iterate the code as it’s not yet functional.
Refactor the Code: Improve code quality and design to meet your team’s or organization’s code standards. Do not make any functional changes.
Run the Test: Run the test again to confirm that it still passes. This should always pass but its worth the 5 second check to make sure you didn’t break anything while refactoring. If it fails, revert back to functional code and refactor from there.
Repeat the Cycle: Proceed to the next test or next feature and repeat the process.
When following these steps, you want to follow the main branch shown in Figure 2. The fail branches are checkpoints and are conditional paths, i.e. you may not always traverse them. There is no shame if you have to though, remember the point is to catch bugs earlier in the software development lifecycle.
That’s a whirlwind introduction to TDD, the Red-Green-Refactor implementation and the actual workflow that I follow when using this in practice.
How and Why I use Test-Driven Development
If it wasn’t already clear, I am a huge advocate for TDD and I use it whenever I’m building software (like our code security solution, VISaR) or data pipelines in my consulting work. I find TDD to be highly effective across a lot of data engineering work for several reasons:
Ensuring Data Quality: In data engineering, datasets are only valuable if they’re trusted and you build trust through consistent quality and reliability. By writing tests first, you can define expected outcomes and behaviors of your data pipelines, data transformations, and data processing workflows at the start of your project. You can catch bugs early on, leading to higher-quality data outputs.
Iterative Development: TDD encourages an iterative development process where small, incremental changes are made and tested thoroughly before moving on. This approach is well-suited for data pipelines where we want deterministic and often idempotent outputs. As you build more sophisticated data pipelines, you’ll need to deal with multiple interconnected components which need testing in a systematic way.
Maintainability and Refactoring: With TDD, the test suite serves as a safety net, ensuring that changes or code refactors don’t break existing functionality. This makes large codebases easier to maintain as you have constant (almost instant) feedback whenever you implement changes. I find this method makes it much easier for agile responses to evolving data requirements and business needs.
Collaboration and Documentation: The tests written in a TDD approach act as documentation which clearly defines the expected behavior and requirements of the code. This facilitates collaboration among team members, as everyone has a shared understanding of the solution’s core functionality at all times.
Faster Feedback Loops: By writing tests first, data engineers can get faster feedback on the correctness and effectiveness of their solutions. Identifying issues more quickly, means quicker remediation and more efficient development.
In addition to those five points which are relevant to most data engineers, the next five are a game-changer in how I work as a solo consultant. As a solo consultant I often work alone on technical implementation and so I need to use workflows which optimize my development. In my consulting work, I’ve become very efficient because I use TDD to:
Detect problems early: Writing tests before code helps me to catch issues sooner, saving me significant time debugging later. I use this as one of the two pillars in my quality assurance process, the other involves LLMs for final code reviews.
Safely Refactor Code: With tests in place, right from the start of a project I can create, update and improve code without fear of breaking things. In the fast paced world of consulting, less unexpected surprises makes me a happy consultant!
Automate Documentation: The tests themselves serve as examples for how code is meant to function. It’s an accelerant for when I need to create documentation and helps with creating automated processes for this.
Reduce Scope Creep: Tests act as simple guidelines which show how solutions should work and since TDD is built on writing “a minimal amount of code”, this reduces my ability to over engineer solutions or for scope creep to become an issue.
Improved code design: TDD encourages building small, modular pieces which leads to cleaner and more organized code. I try to do this anyway but TDD helps keep me honest.
Summary
Test-driven development has always been somewhat controversial and that’s okay. It doesn’t work for everyone and it doesn’t fit every project. BUT if you can get it to work for you then it can help save you time, improve your quality assurance processes, and improve how data engineers can collaborate on a project.
I’m excited to hear your thoughts and reasons for why you do/don’t use test-driven development. Leave a comment!
Thanks for reading! Feel free to follow us on LinkedIn here and here. See you next time! To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.AtLongLast Analytics is a US based consultancy focused on data analytics and data engineering. If you’re interested in our services, contact us through our website.