
Implementing IAM as a Data Engineer: A Practical Example
A practical case study walking you through how I design an IAM solution by combining the use case with personas.
Read time: 7 minutes
This article walks you through the exact workflow we use to design and implement Identity and Access Management (IAM) solutions as a data leader. We apply this simple, practical workflow to design IAM for Azure Storage: define personas, map permissions, and implement role-based access using Terraform. Following these steps ensures secure, maintainable pipelines without overcomplicating your workflow.
Introduction
Data Engineers tend to enjoy building stuff and typically focus their efforts on data transformation and pipelines, with security and access management often getting neglected. I can’t count how often I have heard that it’s “someone else’s job”. I’ve seen good data engineers who never make it past senior level because they don’t learn what makes solutions operational, one of those things being Identity and Access Management (IAM).
I’m not saying you need to become a security engineer or understand all of IAM, understanding the basics is enough to level-up how you build solutions. By learning just a few practical patterns, you can design solutions that are secure-by-design, and prevent accidental data leaks or mishaps.
If you’re new to Identity and Access Management, I suggest checking out our articles covering Azure Fundamentals and IAM anti-patterns used by data teams before continuing with this article.
In this article, we’ll talk through the process of designing an IAM solution for a simple but real-world example: setting up access control for an Azure Storage account with multiple containers. I’ll demonstrate the actual workflow that I would use to examine this use-case, identify key personas and choose relevant permissions.
My Workflow
When creating a new IAM solution (or auditing an existing one) I follow a four-step process so I can understand the use-case, personas involved, and best method of implementation. This process includes:
Understanding the use-case and underlying architecture
Mapping key personas to the use-case and architecture
Identifying appropriate permissions for each persona
Implementation
1. Understanding the Use Case
Our client’s requirement calls for a basic storage solution in Azure that allows data engineers to ingest data into one location, transform it with Python, and then write the cleaned, analysis-ready data to a different location. The data analysts need to access the cleaned data and so they can run analysis and visualization in their own tools.
The client wants the simplest solution possible as there is no dedicated data platform team to maintain any infrastructure. The data engineer and two analysts (one data analyst and one business analyst) on the team need to spend the majority of their time working with the data, not managing the Azure environment.
With this requirement in hand, we go away and do some thinking, then come back to the client and suggest a simple solution. We propose a single Storage Account with two containers:
The first container where ingested data lands. We’ll call this container
raw.The second container stores curated, trusted data for analysis. We’ll call this container
serve.
Figure 1 shows this architecture. The customer owns the data sources and consumption layer so we are only focused on the Storage and Transformation layer.
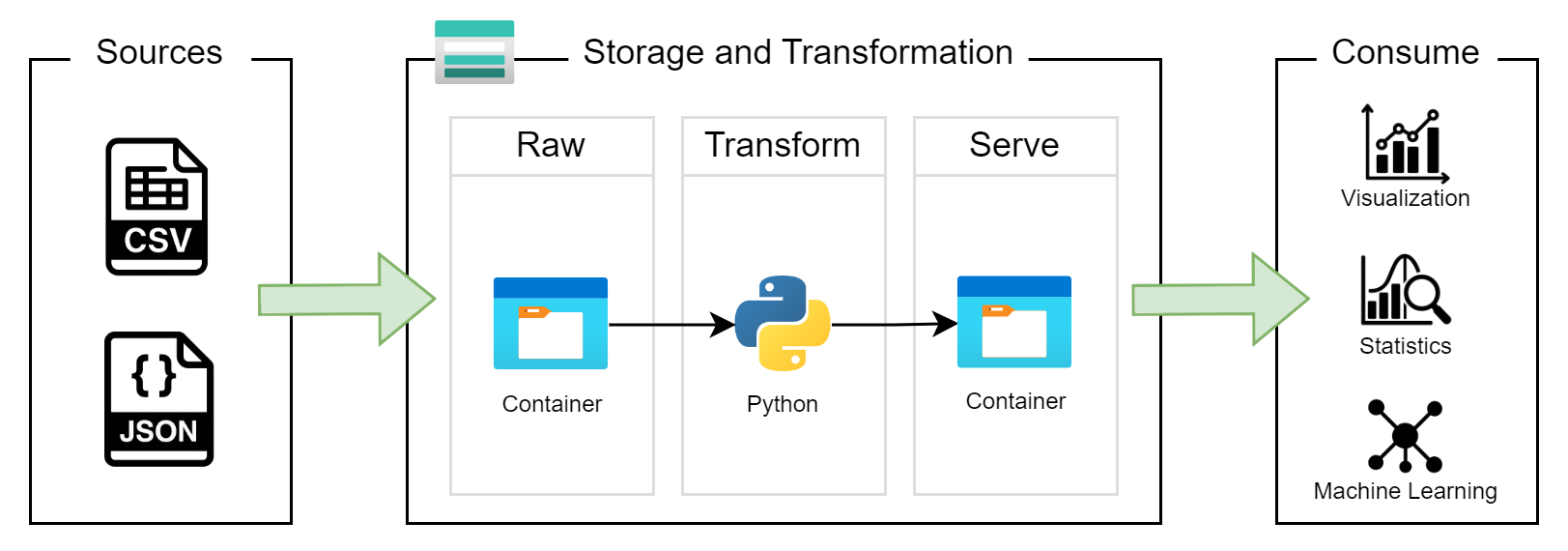
The next step is to identify who’s involved and how they fit with this solution.
2. Mapping Key Personas to the Use Case
With the architecture decided, we want to understand how the data team is going to maintain and actually use this solution. After a workshop with the client, we come up with a persona specification for each role and realize that both the business analyst and data analyst can be grouped into one persona due to their overlapping skills and what they’re permitted to do.
The Persona specifications are:
Data engineer
Needs to be able to ingest raw data, perform data transformation using Python, and write processed data to storage.
Familiar with data transformation, data quality and Python programming.
Cleared to see personally identifiable information (PII) but are the only member of the team who is.
Data Analyst
Needs to be able to access clean data and consume this in Python.
Very capable at statistical analysis and visualization in Python but they have had no training in data quality or Azure cloud services.
NOT permitted to see PII at any stage.
Even these simple persona specifications are powerful as they immediately highlight a risk that we need to handle in our solution. We need to ensure the analysts aren’t given too broad permissions as they might be exposed to PII (leading to compliance issues) or accidentally analyze raw, unprocessed data that leads to wrong conclusions.
In real world scenarios, defining and describing the personas can be much more complex but it’s important to get this step right, even if it takes a while!
With the personas created and understood, we now want to map them to the solution architecture; this is shown in Figure 2. While this diagram is much the same as what we had before, this new diagram combined with the persona specification builds the foundation of our IAM solution.
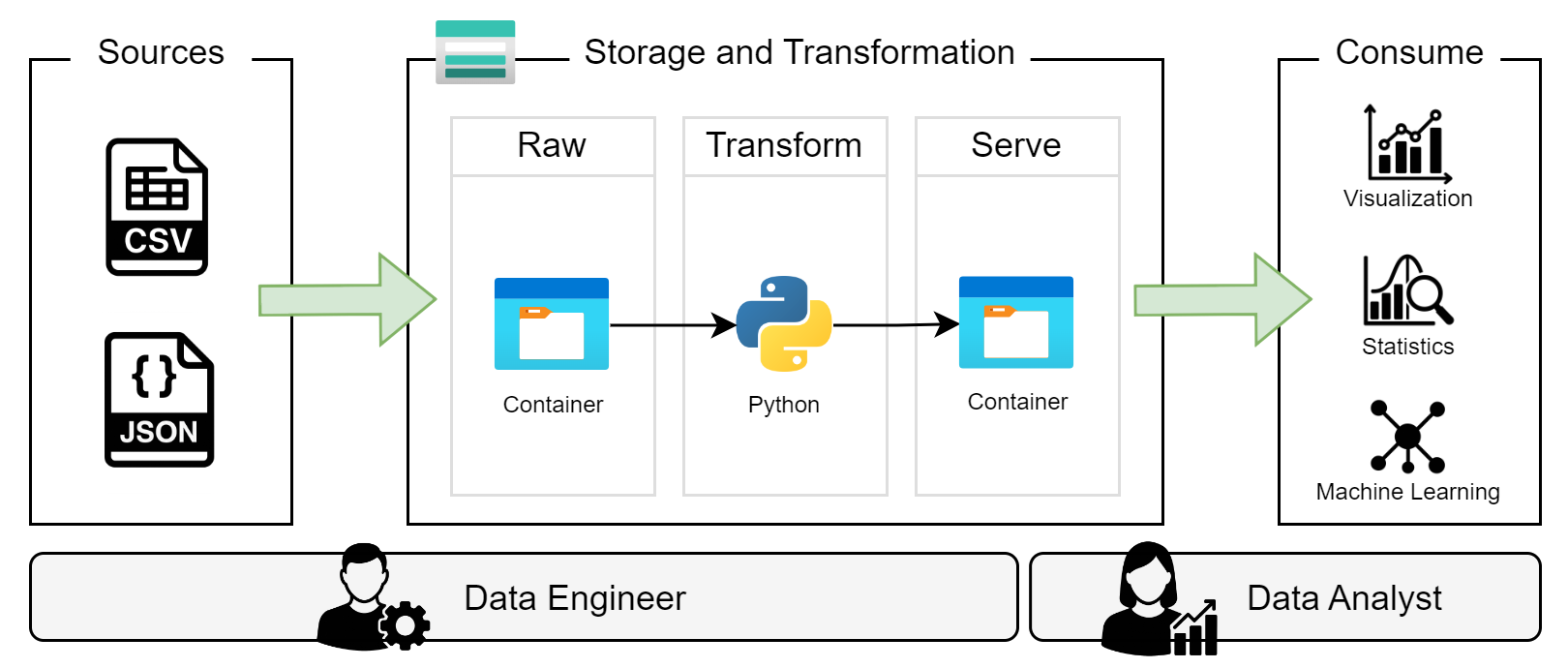
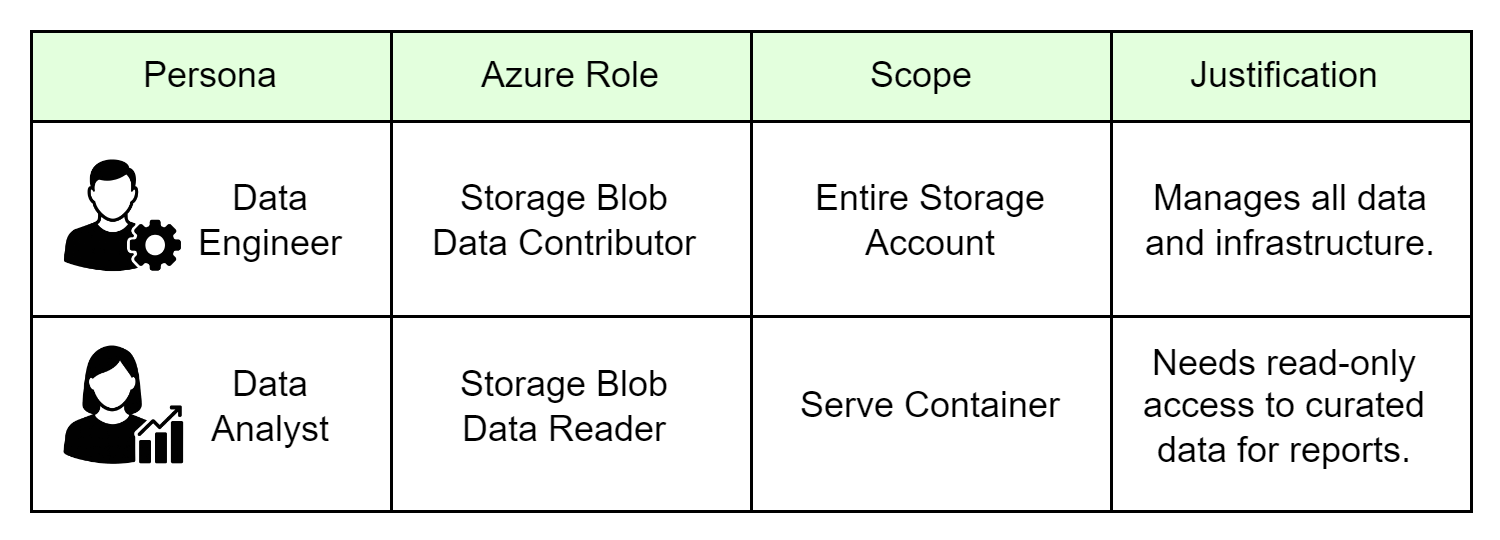
We suggest giving each persona the following access:
Data Engineer
Read, write, and delete access to the entire storage account so they can ingest data into the
rawcontainer, transform it and store curated data to theservecontainer.
Data Analyst
Read-only access to the
servecontainer so they can consume curated datasets for analysis and visualization.
3. Identify Appropriate Permissions
Now we have the personas, it’s important to do some validation that we have met our compliance and governance requirements (as well as the technical). Figure 3 shows a summary of our personas using the Who, How, What, Why framework that we introduced in our previous article on IAM anti-patterns. We use this framework to make sure we satisfy good practices like the Principle of Least Privilege.
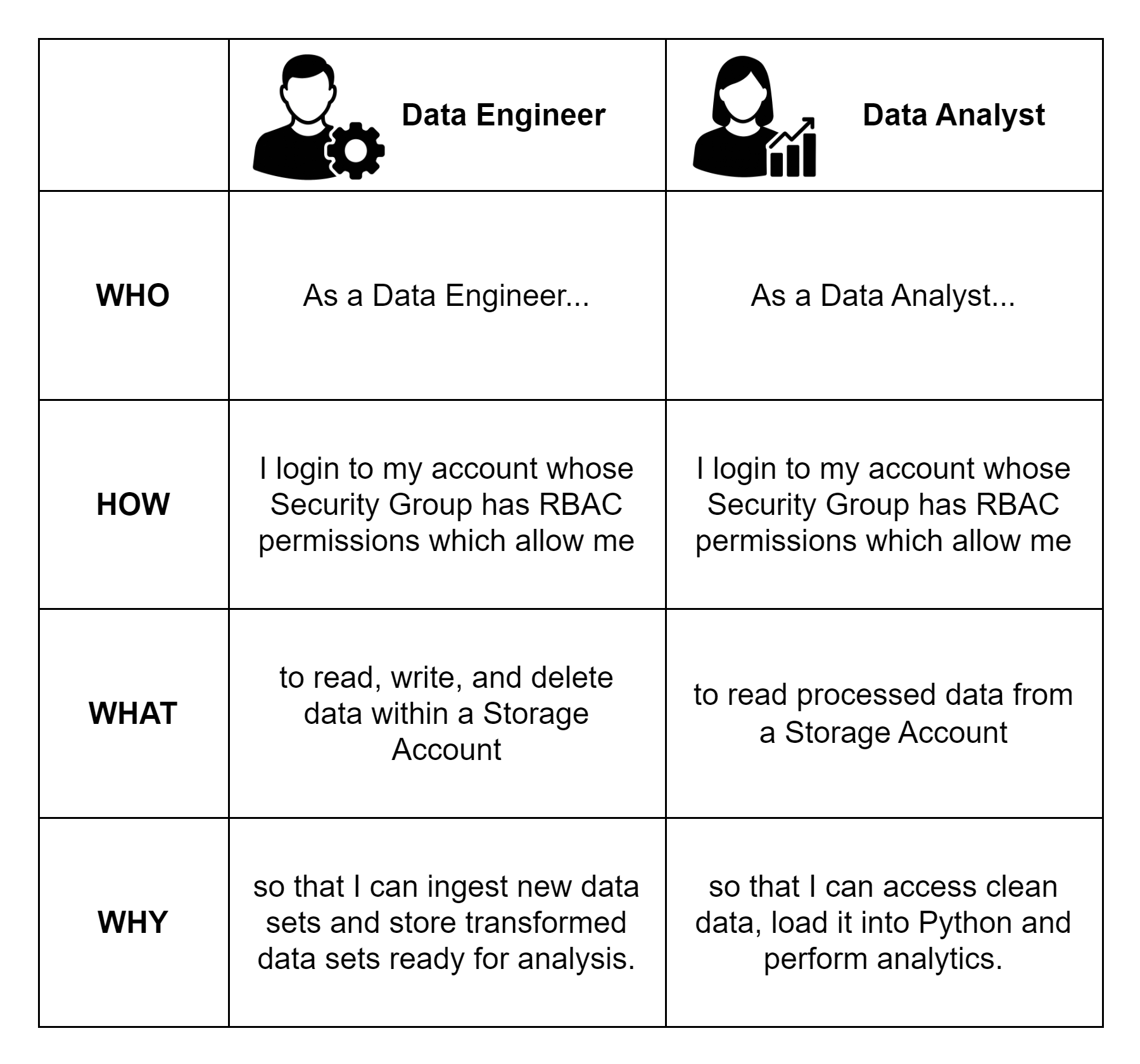
We find it useful to frame my Who, How, What, Why framework contents as a modified user story. This is personal preference and just how we implement this, but use whatever pattern works for you. Just be consistent.
This is the tricky part! We need to look through all of the built-in roles offered by Microsoft and find the one that best match what we need for each persona. This will often be multiple permissions over different resources. We’re looking for the correct permissions and need to make sure that we can apply it at the appropriate scope (e.g. Storage Account vs storage container). We always start with Microsoft’s official documentation and in this case we search for the blob keyword to find appropriate roles. Luckily this only returns a few roles (see Figure 4).
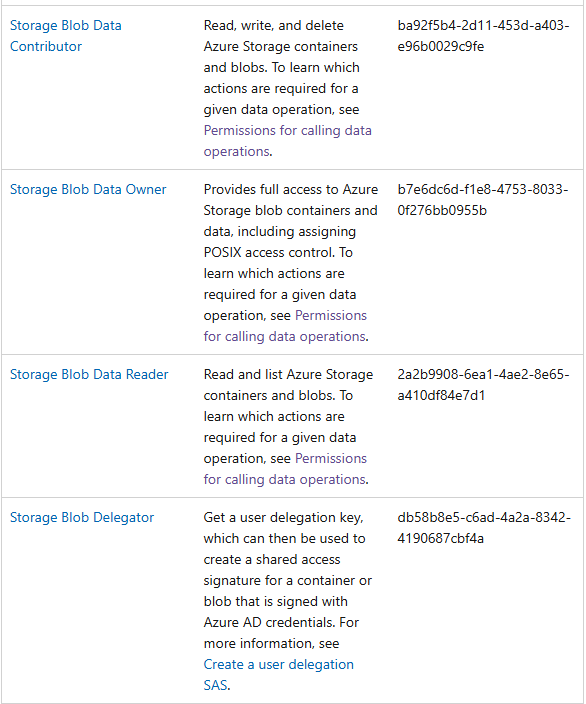
After reading the description of each built-in role, it looks like the Storage Blob Data Contributor is a good fit for our Data Engineer persona. We can apply this that at the Storage Account scope, giving them read, write, and delete permissions to the entire Storage Account and containers within.
For the Data Analyst persona, the Storage Blob Data Reader, looks good as it only gives read permissions and we can apply this to an individual container within the Storage Account. This satisfies our requirement for data access and manages the risk of them accidentally being exposed to PII.
The Azure permissions for both personas are summarized in Figure 5.
It’s important to note that sometimes there isn’t a pre-built role that has the permissions you require and in these cases you will need to create a custom role combining different levels of permissions and scope. This isn’t uncommon but is out of scope of this article.
4. Implementation
At this stage, we have taken our requirement and created a robust IAM solution outlining our personas and relevant permissions. We now need to actually create the personas we need in the Azure environment and assign each persona the relevant permissions. We are going to do this using Terraform, an open-source Infrastructure as Code (IaC) tool that makes it easy to automate the creation, deployment, and management of IAM policies, roles, and permissions across cloud platforms.
Even if you haven’t worked with it before, Terraform should feel familiar to most data engineers as it’s designed to help us build modular, maintainable, and easy to understand projects for infrastructure deployment. This uses all the same concepts that we use when creating software in Python!
We aren’t going to go into all the nitty-gritty details here but we will focus on two important Terraform scripts which show the configuration of Azure resources and personas. We have created a full Terraform project in our GitHub if you want to test this out for yourself (check it out here).
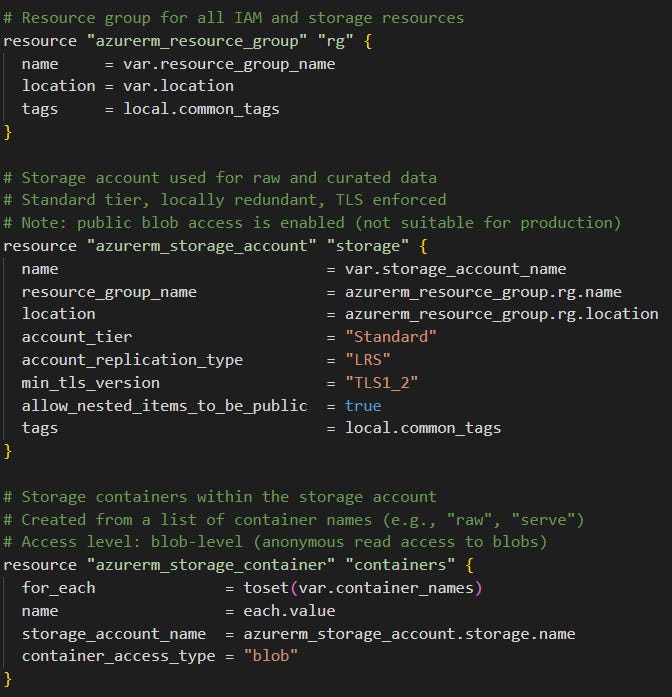
Creating Azure resources using main.tf (figure 6)
In this file we specify the configuration of the Resource Group, Storage Account, and storage containers. You can see that it’s straight forward to create resources using templated Terraform code blocks.
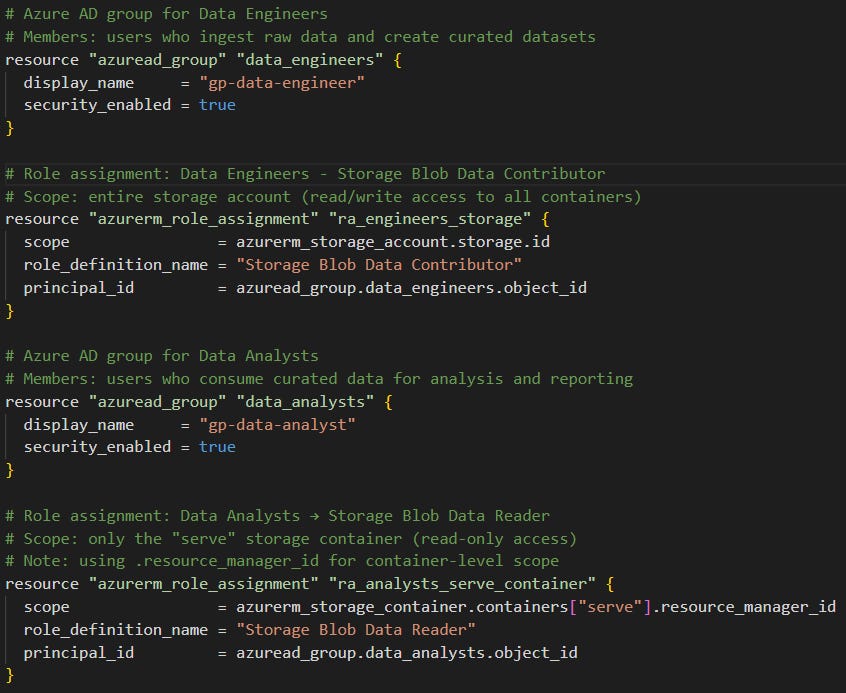
Creating personas using iam.tf (Figure 7).
In this file we specify the configuration of the two security groups (one for the data engineer persona and one for the data analyst persona) and then map permissions to each group by using role assignments. We think that this is where Terraform shines, even if you haven’t used it before, this script is easy to read!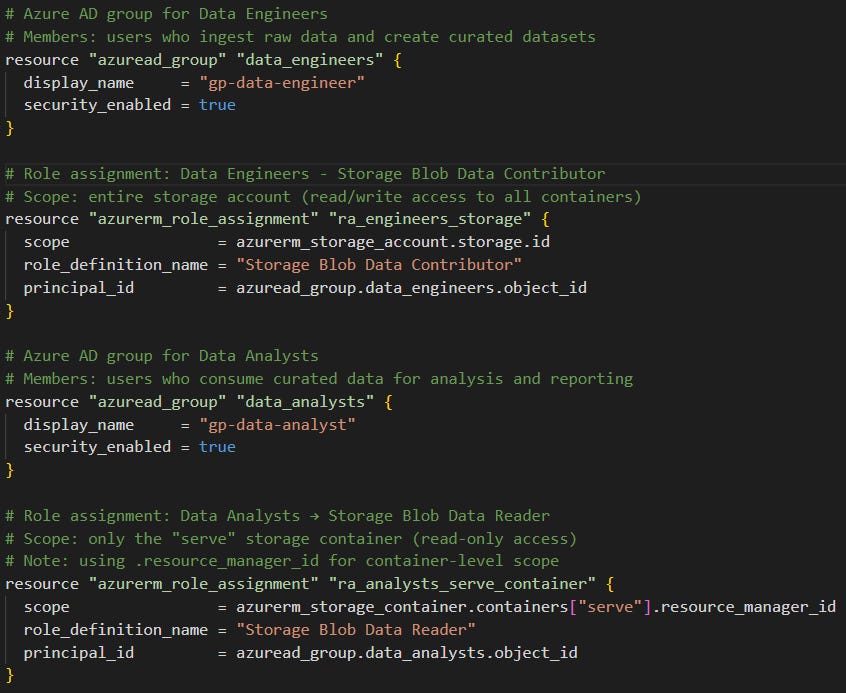
Figure 7: The iam.tf script shows configuration of personas and data access controlled by assigning roles and scope.
Conclusion
In this article, we explored a structured workflow for designing IAM solutions for a small but realistic Azure data storage solution. Starting from understanding the use case, mapping key personas, and identifying their required permissions, we demonstrated how to implement a secure and maintainable solution using Terraform.
Key takeaways that help us build impactful IAM solutions as data engineers:
Understand the architecture and data flow before assigning permissions.
Define personas carefully to avoid over-privileged access and minimize risk.
Apply the Principle of Least Privilege by selecting the right built-in roles or creating custom roles where needed.
Automate deployment with Terraform to create repeatable, maintainable, and auditable IAM configurations.
Even for small teams, investing a little time into Identity and Access Management design ensures that data platforms and cloud infrastructure remain secure, compliant, and easy to maintain. If you’re a data engineer who only builds data pipelines then this is a great opportunity for you to develop your skills in a new area that may help you get that next promotion!
Go check out the Terraform project for this article here. If you found this useful give the repo a star as we are going to be adding to it constantly from now on!
Thanks for reading! Feel free to follow us on LinkedIn here and here. See you next time! To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.