
Quality Assurance in Data Engineering and Analytics: Building Robust Data Products
Most teams focus on catching broken data but I prefer to stop it from breaking in the first place. In this article I discuss how QA helps to build trusted data products faster.
Read time: 6 minutes
I see many data teams interchangeably use the terms testing and monitoring, leading to a misunderstanding of where quality assurance and quality control work truly happens. Testing the final output of a pipeline, asking “does this look right?”, is Quality Control (QC). It’s valuable but inherently reactive.
Quality Assurance (QA), on the other hand, focuses on stopping defects before they enter the system. QA is not about catching bad data; it’s about preventing bad logic. As organizations increasingly rely on data products for strategic decision-making, QA becomes a foundational capability. It’s no longer just a nice-to-have.
This article outlines the core pillars that I think are needed to implement QA effectively; Strategy, People, and Process, and shows how data teams can move from reactive output checking to proactive, engineering-driven quality practices. If you’d like a 3 minute introduction or refresher to Quality Assurance and Quality Control, click here to read our previous article.
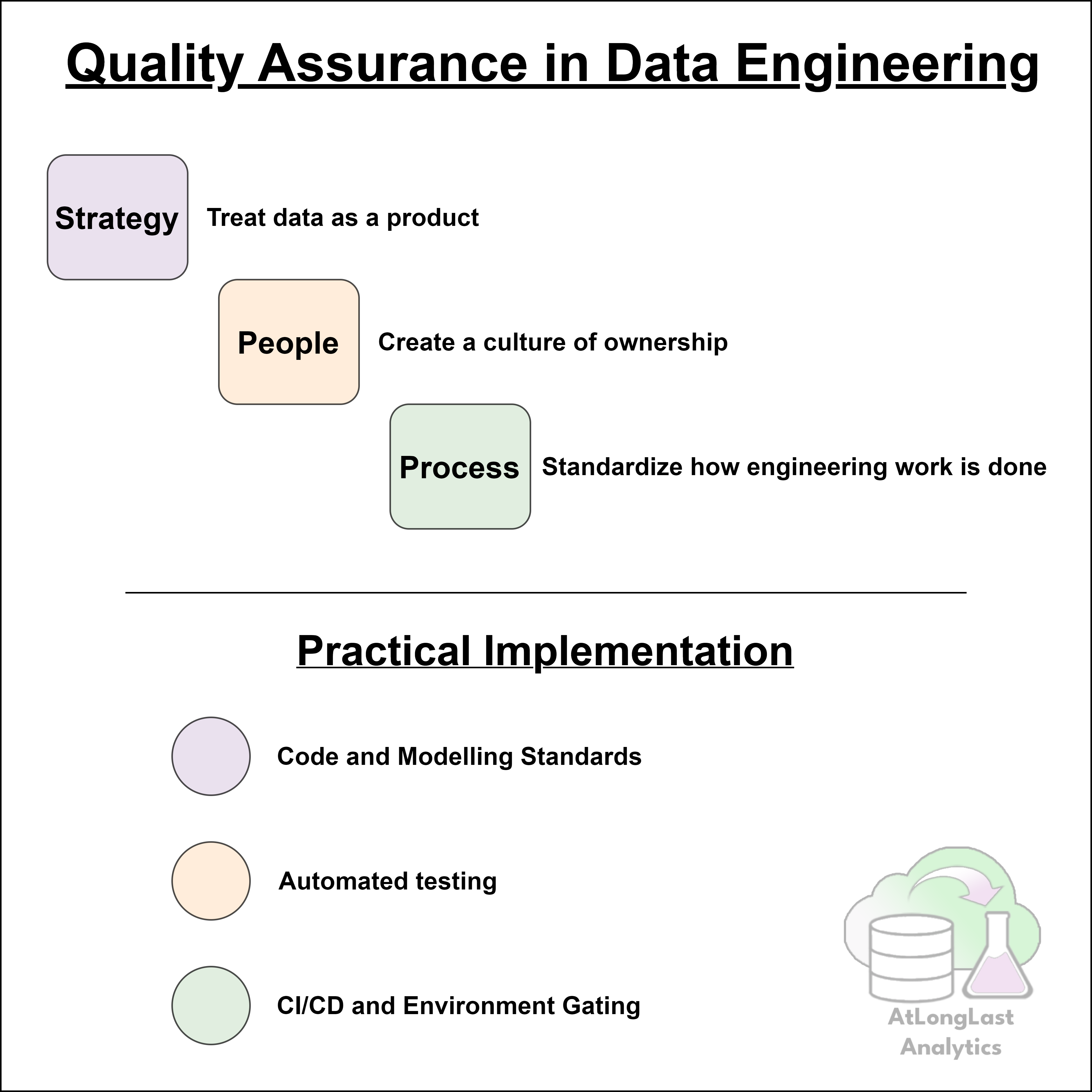
I. The QA Foundation: Strategy, People, and Process
Building robust data products needs more than just tools; it requires a holistic approach that aligns business priorities, engineering practices, and team culture. Before writing a single test, you need this foundation in place.
Most QA initiatives fail not because engineers lack technical skill, but because teams lack alignment. Good QA relies on having someone who understands engineering, business priorities, and communication. This QA champion needs to be able to translate between the C-suite and technical teams and advocate for quality as a real asset.
Strategy: Treating Data as a Product
The success of QA efforts depends heavily on whether the business treats data as a strategic product rather than an IT by-product. QA rarely gets prioritized unless leadership explicitly values reliability and long-term maintainability. I’ve seen many organizations fall into the trap of never considering it to be more than just nice-to-have.
When organizations view data pipelines, AI applications, cloud infrastructure, and analytics assets as core business products, quality becomes non-negotiable. The definition of quality also evolves, from simply ‘is this number right?’ to ‘is the system that produces this number trustworthy?’
This shift is foundational. Without it, QA becomes an afterthought.
People: Creating a Culture of Ownership
Once quality is a strategic priority, the next step is cultivating a team that embraces responsibility and works collaboratively to uphold standards.
A mature QA culture makes quality everyone’s responsibility, not just a designated tester’s. This includes three core components:
Ownership: Engineers must understand that they own the quality of their work. This requires clear standards of what ‘good’ looks like, time allocated for QA tasks, and accountability for QA/QC outcomes. When engineers feel empowered, not rushed, they have an environment that encourages more performant, cleaner, and more maintainable code.
Show, Don’t Tell: Teams need to move from ‘I hope this works’ to ‘I have proven this works'. By involving stakeholders early and demonstrating functionality as it’s developed, you build trust, reduce surprises and secure future buy-in.
Collaboration: Peer review is central to QA. It should feel like a safety net, not a critique. A culture that welcomes feedback leads to drastically improved reliability and consistency across codebases.
Process: Standardize How Engineering is Done
Moving from strategic to tactical action is all about codifying these values into repeatable workflows. Mature data teams adopt structured engineering practices by: enforcing version control requiring design documentation, standardizing development lifecycles, and keeping documentation alive and actively used.
I’ve seen many teams produce a wave of documentation early on, only for it to become stales and ignored a few weeks later. Effective QA requires processes that people actually use, because they integrate into their daily ways of working.
With these foundations in place, teams can implement the concrete components of QA: Standards, Testing, and Automation.
With this foundation in place, we move to the concrete Actions that enforce quality: Standards, Testing, and Automation.
II. QA Implementation
1. Code and Modeling Standards: Enforcing Consistency
Before writing complex tests, teams must establish a baseline of consistency. Inconsistent code leads to inconsistent data and makes reviews cognitively taxing.
Start with clear, enforceable standards:
Coding Standards
Use stye guides and tools that enforce readability and maintainability, e.g. style guides like PEP8, linters like flake8 or black, and standardized conventions for casing, naming and formatting.
When every engineer writes code differently, reviews are slower and bugs slip through.
Data Modelling Standards
Good modeling standards make data easier for both technical and business users to understand. A few simple conventions go a long way: use prefixes for table names (e.g. dim_, fct_, stg_), clear naming conventions, and consistent definitions of granularity and purpose.
Remember that investing in these now will pay dividends in the long term.
Project and Directory Structure
A repeatable layout simplifies onboarding of new team members and let’s engineers start new features by immediately building. Engineers shouldn’t have to search for tests or configuration files, they should always live in the space place.
Consistency enables automation, and automation enables scale.
2. Automated Testing: The Core of Data QA
Manual testing doesn’t scalable. If engineers need to manually query outputs after every change, testing will eventually stop, and defects will slip through.
Unit Tests (Logic Validation)
Unit tests validate small pieces of logic in isolation. They don’t require real data. They are a fast, lightweight method to catch logical errors early in the development cycle, long before they hit production systems or introduce data quality issues.
Integration Tests (System Interaction)
Integration tests validate how components interact, especially external services, APIs, and storage systems. These tests are particularly valuable when using components managed by different vendors, e.g. an API a data provider and Storage Accounts hosted in Azure, both accessed from privately networked Virtual Machines (VM).
Transformation Tests (Data Logic Validation)
These tests validate transformations using controlled input and expected output data, typically using mock data instead of the real thing. These are very useful to protect against regressions and ensure logic behaves as intended.
3. CI/CD Pipelines and Environment Gating
Even the best tests in the world are useless if engineers don’t run them. QA must be automated through Continuous Integration and Continuous Deployment (CI/CD). This is especially true if your data team doesn’t have resident DevOps engineers!
Continuous Integration (CI)
Every pull request should trigger automated checks, including: static analysis via linters, security scans for exposed credentials, unit and integration tests, and code coverage requirements.
Code cannot be merged until all checks pass.
Continuous Deployment (CD)
QA depends on clean separation between environments. No one should be developing directly in production. It’s common practice to have Dev for experimentation, Test/Staging that mirrors production where integration tests run, and Prod as the live environment.
Promotion from one environment to the next should require passing test and peer approval - no exceptions.
Infrastructure-as-Code (IaC)
Infrastructure should be version-controlled and tested just like application code. Tools like Terraform allow teams to review and approve infrastructure changes, prevent misconfiguration and accidental destruction.
III. Conclusion
Many teams believe QA slows them down. And yes, writing tests, configuring CI, and following naming conventions takes upfront time. But the long-term benefits are enormous and in my experience is almost always a velocity multiplier.
Teams without QA will eventually spend too much of their time fixing broken pipelines, backfilling corrupted tables, and managing stakeholder frustration. This reactive cycle halts progress on new work and creates instability across data products.
QA reverses this dynamic by catching defects during development, when they’re cheapest to fix. When engineers trust that the pipeline will catch errors automatically, they can build faster and deliver features with confidence.
Ask yourself, is your current QA processes are slowing you down or speeding you up?
Thanks for reading! Feel free to follow us on LinkedIn here and here. See you next time! To receive new posts and support our work, become a free or paid subscriber today.
If you enjoyed this newsletter, comment below and share this post with your thoughts.